733. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods
Justus Arweiler, Indra Jungjohann, Aparna Muraleedharan, Heike Leitte, Jakob Burger, Kerstin Münnemann, Fabian Jirasek, Hans Hasse, Arxiv, (2025), DOI: 10.5281/zenodo.17395544
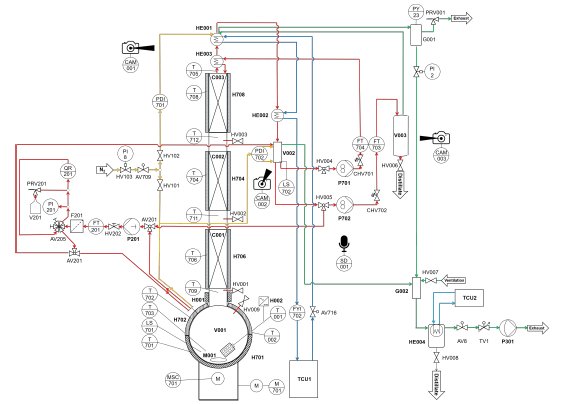
Machine learning (ML) holds great potential to advance anomaly detection (AD) in chemical processes. However, the development of ML-based methods is hindered by the lack of openly available experimental data. To address this gap, we have set up a laboratory-scale batch distillation plant and operated it to generate an extensive experimental database, covering fault-free experiments and experiments in which anomalies were intentionally induced, for training advanced ML-based AD methods. In total, 119 experiments were conducted across a wide range of operating conditions and mixtures. Most experiments containing anomalies were paired with a corresponding fault-free one. The database that we provide here includes time-series data from numerous sensors and actuators, along with estimates of measurement uncertainty. In addition, unconventional data sources – such as concentration profiles obtained via online benchtop NMR spectroscopy and video and audio recordings – are provided. Extensive metadata and expert annotations of all experiments are included. The anomaly annotations are based on an ontology developed in this work. The data are organized in a structured database and made freely available via doi.org/10.5281/zenodo.17395544. This new database paves the way for the development of advanced ML-based AD methods. As it includes information on the causes of anomalies, it further enables the development of interpretable and explainable ML approaches, as well as methods for anomaly mitigation.